
Chapter 9: Working with Existing PDFs
Contents
9.1 OpenDocument and OpenDocumentBinary Methods
So far, we have only worked with new PDF documents created via PdfManager's CreateDocument method. AspPDF works equally well with existing PDFs.
To obtain an instance of the PdfDocument object representing an existing PDF document, the PdfManager object provides the OpenDocument method which expects two arguments: a physical path to the PDF document, and an optional password (in case the documented being opened is password-protected).
OpenDocument returns Nothing if the PDF document being opened requires a password and the password argument is empty. If the specified password is valid, or if the document does not require a password at all, the method returns an instance of the PdfDocument object. In all other cases (invalid password, invalid path, corrupt PDF document, etc.) the method throws an error exception.
The following code fragment opens a PDF document from the file mydoc.pdf:
Set Doc = Pdf.OpenDocument("c:\path\mydoc.pdf")
If Doc Is Nothing Then
Response.Write "This PDF is password-protected."
' Obtain a password from user and try again
Set Doc = Pdf.OpenDocument("c:\path\mydoc.pdf", Pwd)
End If
...
IPdfDocument objDoc = objPdf.OpenDocument("c:\\path\\mydoc.pdf", Missing.Value);
if( objDoc == null )
{
lblResult.Text = "This PDF is password-protected.";
// Obtain a password from user and try again
objDoc = objPdf.OpenDocument("c:\\path\\mydoc.pdf", strPwd);
}
...
The OpenDocumentBinary method is similar to OpenDocument except that it opens a document from a binary memory array instead of disk. This method is useful when a PDF document to be opened resides in a database table as a BLOB. An ADO recordset field of the datatype Binary (SQL Server) or OLE Object (Access) can be passed as the first argument to OpenDocumentBinary, as follows:
Like OpenDocument, the OpenDocumentBinary method takes a password as the second optional argument, and its return value is the same as that of OpenDocument.
9.2 Template Fill-in
Once a PdfDocument object representing an existing PDF is obtained via the OpenDocument or OpenDocumentBinary methods, it can be used the same way as a new documents. Its various properties can be read and modified, pages drawn on, added or removed, etc.
Existing PDFs can be drawn on the same way as new documents. This enables your application to populate a document template with dynamic data (such text, images, drawings, etc.) For example, a standard blank PDF form can be opened and filled out with database- or user-supplied information.
Dim arrY
Dim arrText
arrX = Array(100, 325, 455, 512, 550, 100, 100)
arrY = Array(660, 660, 660, 687, 687, 602, 577)
arrText = Array("John A.", "Smith", "123-56-7890", "1,234",_
"00", "4300 Cherry Ln.", "New York, NY 10001" )
Set Pdf = Server.CreateObject("Persits.Pdf")
' Open blank PDF form from file
Set Doc = Pdf.OpenDocument( Server.MapPath("1040es.pdf") )
Set Font = Doc.Fonts("Helvetica-Bold")
' Obtain the only page's canvas
Set Canvas = Doc.Pages(1).Canvas
Set Param = Pdf.CreateParam
' Fill out three copies of the 1040ES
For i = 0 to 2
' Go over all items in arrays
For j = 0 to UBound(arrX)
Param("x") = arrX(j)
Param("y") = arrY(j) - 263 * i
' Draw text on canvas
Canvas.DrawText arrText(j), Param, Font
Next ' j
Next ' i
' Save document, the Save method returns generated file name
Filename = Doc.Save( Server.MapPath("form.pdf"), False )
int [] arrY = {660, 660, 660, 687, 687, 602, 577};
String [] arrText = {"John A.", "Smith", "123-56-7890", "1,234",
"00", "4300 Cherry Ln.", "New York, NY 10001"};
IPdfManager objPdf = new PdfManager();
// Create empty document
IPdfDocument objDoc = objPdf.OpenDocument(Server.MapPath("1040es.pdf"), Missing.Value);
IPdfFont objFont = objDoc.Fonts["Helvetica-Bold", Missing.Value];
// Obtain the only page's canvas
IPdfCanvas objCanvas = objDoc.Pages[1].Canvas;
IPdfParam objParam = objPdf.CreateParam( Missing.Value );
// Fill out three copies of the 1040ES
for( int i = 0; i < 3; i++ )
{
// Go over all items in arrays
for( int j = 0; j < arrX.Length; j++ )
{
objParam["x"].Value = arrX[j];
objParam["y"].Value = arrY[j] - 263 * i;
// Draw text on canvas
objCanvas.DrawText( arrText[j], objParam, objFont );
}
}
// Save document, the Save method returns generated file name
String strFilename = objDoc.Save( Server.MapPath("form.pdf"), false );
Click the links below to run this code sample:
9.3 Page Management
AspPDF makes it possible to insert pages into existing PDF documents, and also remove pages from them.
9.3.1 Page Insertion
Pages are added to a documents via the Doc.Pages collection. The Add method of this collection accepts three optional arguments: the page width, height, and a 1-based insert-before index. By default, a page is appended to the end of the document. If the insert-before argument is specified, the new page is inserted right before the one pointed to by this argument. Once a new page is inserted, it is assigned the insert-before index, and all the following pages' indices are incremented by one.
9.3.2 Page Removal
Any page can be removed from the document via the PdfPages.Remove method. This method accepts a single argument, the 1-based index of a page to be removed.
When the Remove method is called, AspPDF does not really remove a page from the document, it just marks it as deleted, and removes a reference to it from the internal page tree. The page effectively disappears from the document, but the document file does not shrink. In fact, it even becomes slightly bigger as new information has to be appended to the end of the document to indicate that one of its structures (a page) is now deleted.
9.3.3 Drawing on Page Background
The code sample 09_form.asp/aspx (see the previous section of this chapter) uses the Page.Canvas property to draw text information on a form. In general, using Page.Canvas on a page within an existing document causes new graphics and text to appear on top of the existing drawing on that page.
If new graphics belongs underneath the existing drawing (such as, a watermark with a corporate logo), the property Page.Background must be used instead. This property returns a separate instance of the PdfCanvas object, and whatever is drawn on it will appear on the bottom of the content stack.
9.3.4 Code Sample
The following code sample opens a simple two-page documents TwoPageDoc.pdf and performs the following operations with it:
- a new page is inserted before the first page;
- another page is inserted after what used to be the first page (and now second);
- page 2 of the original document (which is now page 4) is removed;
- a background image is drawn on all three remaining pages.
Set Doc = Pdf.OpenDocument( Server.MapPath("TwoPageDoc.pdf") )
' insert page before 1st
Set Page1 = Doc.Pages.Add(, , 1)
' insert page after 2nd
Set Page2 = Doc.Pages.Add(, , 3)
' Remove page 4 (page 2 in original doc)
Doc.Pages.Remove 4
' Draw background image on all 3 remaining pages
Set Image = Doc.OpenImage( Server.MapPath("exclam.gif") )
For Each Page in Doc.Pages
Page.Background.DrawImage Image, "x=70, y=220; scalex=2; scaley=2"
Next
Filename = Doc.Save( Server.MapPath("pages.pdf"), False )
// Open blank PDF form from file
IPdfDocument objDoc = objPdf.OpenDocument(Server.MapPath("TwoPageDoc.pdf"), Missing.Value);
// insert page before 1st
IPdfPage objPage1 = objDoc.Pages.Add(Missing.Value, Missing.Value, 1);
// insert page after 2nd
IPdfPage objPage2 = objDoc.Pages.Add(Missing.Value, Missing.Value, 3);
// Remove page 4 (page 2 in original doc)
objDoc.Pages.Remove( 4 );
// Draw background image on all 3 remaining pages
IPdfImage objImage = objDoc.OpenImage( Server.MapPath("exclam.gif"), Missing.Value );
foreach( IPdfPage objPage in objDoc.Pages )
{
objPage.Background.DrawImage(objImage, "x=70,y=220;scalex=2;scaley=2" );
}
// Save document, the Save method returns generated file name
String strFilename = objDoc.Save( Server.MapPath("pages.pdf"), false );
Click the links below to run this code sample:
When drawing on an existing document, the text (graphics) sometimes appears inverted, shifted, scaled, or even does not appear on the page at all.
As mentioned in Chapter 4, all drawing on a page occurs in the default user coordinate space with the origin in the lower-left corner of the page and the X and Y axes extending horizontally to the right and vertically upwards, respectively. Some PDF documents change this default coordinate space by shifting the origin, changing axis directions, modifying the unit length, etc. (see Section 4.5.1 - Transformation Martix).
All drawing operations performed on such a document inherit the changed coordinate system, causing unpredictable results in terms of the location, orientation and size of objects being drawn.
Starting with Version 1.5, AspPDF offers a new method, PdfPage.ResetCoordinates, which brings the coordinate system on the page back to the defaults. Just call this method before drawing text or graphics, as follows:
Set Page = Doc.Pages(1)
Page.ResetCoordinates
Page.Canvas.DrawText "text", ...
9.4 Content Extraction
AspPDF is capable of extracting raw text information from PDF documents for searching and indexing purposes. Text is extracted from an individual page via the ExtractText method of the PdfPage object. ExtractText takes an optional parameter object or parameter string (described below.) This method always returns text strings in Unicode format.
Text extraction with coordinates, introduced in Version 2.8, is described in Section 17.7 - Structured Text Extraction.
9.4.1 Code Sample
The following code sample extracts and prints out text data from all pages of a PDF (we use the 1-page file 1040es.pdf from section 9.2):
' Open a PDF file for text extraction
Set Doc = Pdf.OpenDocument( Server.MapPath("1040es.pdf") )
Dim TextString
For Each Page in Doc.Pages
TextString = TextString & Page.ExtractText
Next
Response.Write Server.HtmlEncode( TextString )
// Open a PDF file for text extraction
IPdfDocument objDoc = objPdf.OpenDocument( Server.MapPath("1040es.pdf"), Missing.Value );
String strText = "";
foreach( IPdfPage objPage in objDoc.Pages )
{
strText += objPage.ExtractText(Mssing.Value);
}
lblResult.Text = Server.HtmlEncode( strText );
Click the links below to run this code sample:
9.4.2 Possible Text Extraction Problems
PDF text extraction is not always reliable, sometimes it produces split and conjoined words, or even unreadable gibberish.
9.4.2.1 Split and Conjoined Words
Unlike HTML or Word documents, PDFs do not usually contain blocks of meaningful, readable text. Instead, they contain text drawing operators that reference short phrases, individual words, word parts and even separate characters. As a result, an attempt to extract text information from a PDF document often yields split and conjoined words. For example, the phrase "Brown dog" may come out as "Browndog" (conjoined words) or "Bro wn d og" (split words).
9.4.2.2 Gibberish
Many PDF documents, especially those using non-Latin alphabets, do not use strings of readable characters to display text at all. Instead, they use "glyph codes" which are numbers identifying character appearances in a font file. "Good" PDF documents also provide mapping tables (referred to as ToUnicode maps) enabling a consumer application to convert those codes back to human-readable characters. However, not every PDF document is "good". Those that aren't cannot technically be read. An attempt to extract text from such a document yields gibberish. Copying information from such a file via clipboard from Acrobat Reader will fail as well.
9.4.2.3 Unknown Encoding
Certain foreign-language PDF documents use ASCII characters in the 129 - 255 range to display text information. Copying and pasting from such documents with Acrobat Reader usually produces unreadable text. However, AspPDF is capable of extracting text from these documents and converting them into Unicode, but a code page must be passed to ExtractText method via the CodePage parameter, such as "CodePage=1251" (Cyrillic), or "CodePage=1256" (Arabic), etc.
9.4.3 Permission Issues
A secure document may disallow content extraction by clearing Bit 5 of its permission flags (see Section 8.1.2). To be in compliance with Adobe PDF licensing requirements, AspPDF enforces this permission flag. For the content extraction functionality to work, a secure document with Bit 5 cleared must be opened with the owner password , or an error exception will be thrown.
9.5 Page Extraction
Starting with Version 1.2, AspPDF is capable of extracting individual pages from a PDF document via the ExtractPages method of the PdfDocument object. This method accepts a PdfParam object or parameter string as an argument, and returns a new instance of PdfDocument comprised of one or more pages extracted from the original document. The 1-based indices of pages to be extracted are specified via the parameters Page1, Page2, Page3, etc. This method can only be called on an existing, not new, PDF document.
The following code fragment opens a document, extracts pages 5 and 3 from it, and saves the resultant 2-page document to disk. Pages 5 and 3 of the original document become pages 1 and 2 of the new document, respectively.
Set Doc = Pdf.OpenDocument("c:\path\original.pdf")
Set NewDoc = Doc.ExtractPages("Page1=5; Page2=3")
NewDoc.Save "c:\path\extractedpages.pdf"
The ExtractPages method looks for the parameters Page1, Page2, etc., until a break in the sequence is encountered.
NOTE: The PdfDocument object returned by ExtractPages cannot be used to manipulate the newly extracted pages. In fact, this object cannot be used for anything other than saving (to disk, memory or an HTTP stream). If you do need to make changes to it, you must save it first and then re-open, as follows:
Set NewDoc = Doc.ExtractPages("Page1=5; Page2=3")
Set Doc2 = Pdf.OpenDocumentBinary( NewDoc.SaveToMemory )
Doc2.Pages(1).Canvas.DrawText...
9.6 Drawing Other Documents' Pages
As of Version 2.3, AspPDF enables the page of another existing document to be turned into a PdfGraphics object and then drawn on this document at an arbitrary location or locations, with rotation and scaling applied, if necessary. PdfGraphics objects are described in detail in Chapter 5.
To turn another document's page into an instance of the PdfGraphics object, use the method PdfDocument.CreateGraphicsFromPage. This method expects two arguments: the instance of another document and the 1-based index of the page within that document to be converted. If the document is encrypted, it needs to have been opened using the owner password.
The method returns an instance of the PdfGraphics object which can then be drawn on any page of this document via the PdfCanvas.DrawGraphics method.
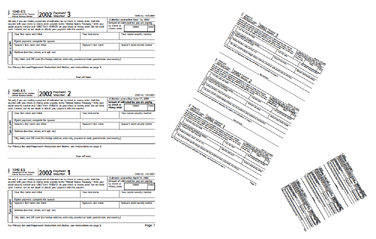
' Create a new document
Set Doc = Pdf.CreateDocument
Set Page = Doc.Pages.Add
' Open existing PDF
Set AnotherDoc = Pdf.OpenDocument( Server.MapPath("1040es.pdf") )
' Turn page 1 into a PdfGraphics object
Set Graphics = Doc.CreateGraphicsFromPage( AnotherDoc, 1 )
' Draw on this document several times
Page.Canvas.DrawGraphics Graphics, "x=10; y=500; scalex=0.3; scaley=0.3"
Page.Canvas.DrawGraphics Graphics, "x=180; y=600; scalex=0.2; scaley=0.2; angle=-30"
Page.Canvas.DrawGraphics Graphics, "x=300; y=550; scalex=0.1; scaley=0.1; angle=-60"
' Save document, the Save method returns generated file name
Filename = Doc.Save( Server.MapPath("page2graphics.pdf"), False )
// Create a new document
IPdfDocument objDoc = objPdf.CreateDocument( Missing.Value );
IPdfPage objPage = objDoc.Pages.Add( Missing.Value, Missing.Value, Missing.Value );
// Open existing PDF
IPdfDocument objAnotherDoc = objPdf.OpenDocument( Server.MapPath("1040es.pdf"), Missing.Value );
// Turn page 1 into a PdfGraphics object
IPdfGraphics objGraphics = objDoc.CreateGraphicsFromPage( objAnotherDoc, 1 );
// Draw on this document several times
objPage.Canvas.DrawGraphics( objGraphics, "x=10; y=500; scalex=0.3; scaley=0.3" );
objPage.Canvas.DrawGraphics( objGraphics, "x=180; y=600; scalex=0.2; scaley=0.2; angle=-30" );
objPage.Canvas.DrawGraphics( objGraphics, "x=300; y=550; scalex=0.1; scaley=0.1; angle=-60" );
// Save document, the Save method returns generated file name
String strFilename = objDoc.Save( Server.MapPath("page2graphics.pdf"), false );
Click the links below to run this code sample:

Using CreateGraphicsFromPage is the most efficient way to create a multi-page document based on a single-page PDF template. See Article PS130905190 of our Knowledge Base for a code sample.
UPDATE: As of Version 3.2, one or more instances of the PdfGraphics object can be designated as templates for a PdfDocument object via the method PdfDocument.AddTemplate. This way, every time a new page is added to this document, all applicable template graphics are automatically drawn on this page and become this page's background. This functionality is described in detail in Section 15.8 - Templates.

